目前所在的公司在半年前,全部从单体react应用切换到qiankun框架下,变成子应用。因为我的前端小组开发的是一用低代码的前端工程,这些工程是分成三部分的:应用搭建器、应用各种平台下的运行时,以及平台业务逻辑。普通的业务逻辑和应用搭建器,可以和qiankun的父应用共用一套监控项目,通过路由、资源前缀、接口名等等,去分别监控(比如我只看low-code-proj-1这个工程的监控信息)。问题出现在运行时工程,这个工程是所有用户所公用的,在路由、接口、资源等都没有进行特定租户的区分,因此就无法实现具体某个APP或者某个租户级别的监控了,而在业务的安全性上是需要这种信息的。
几个大前提
- 乾坤是一个spa应用,基于single-spa包装。
- 子程序目前都是通过网络异步加载js代码执行,而得到表现。
- 子程序执行的时候,浏览器onload等事件,早已经发生过了,性能无法准确统计。
- 所有工程都在同一个arms监控大盘,不能单独拉出来分析,甚至落实到人头上。
- 乾坤在实现某种“茴”字写法的同时,也让一些基础工作变得难以展开,比如今天说的监控。这都是框架设计者们做的稀烂的部分。
怎么实现?
在arms文档里有明确说明,可以 createExtraInstance。
- 爹应用singleton
- 儿子应用createExtraInstance
- 每工程都使用不同的pid,自己统计自己的数据
在具体的工程里,打开enableInstanceAutoSend,这个在文档里却没有说明,属于arms文档写的稀烂的部分,对于new出来的实例如何使用几乎没有任何说明,你只能从探针源码里找到这个配置项,如下图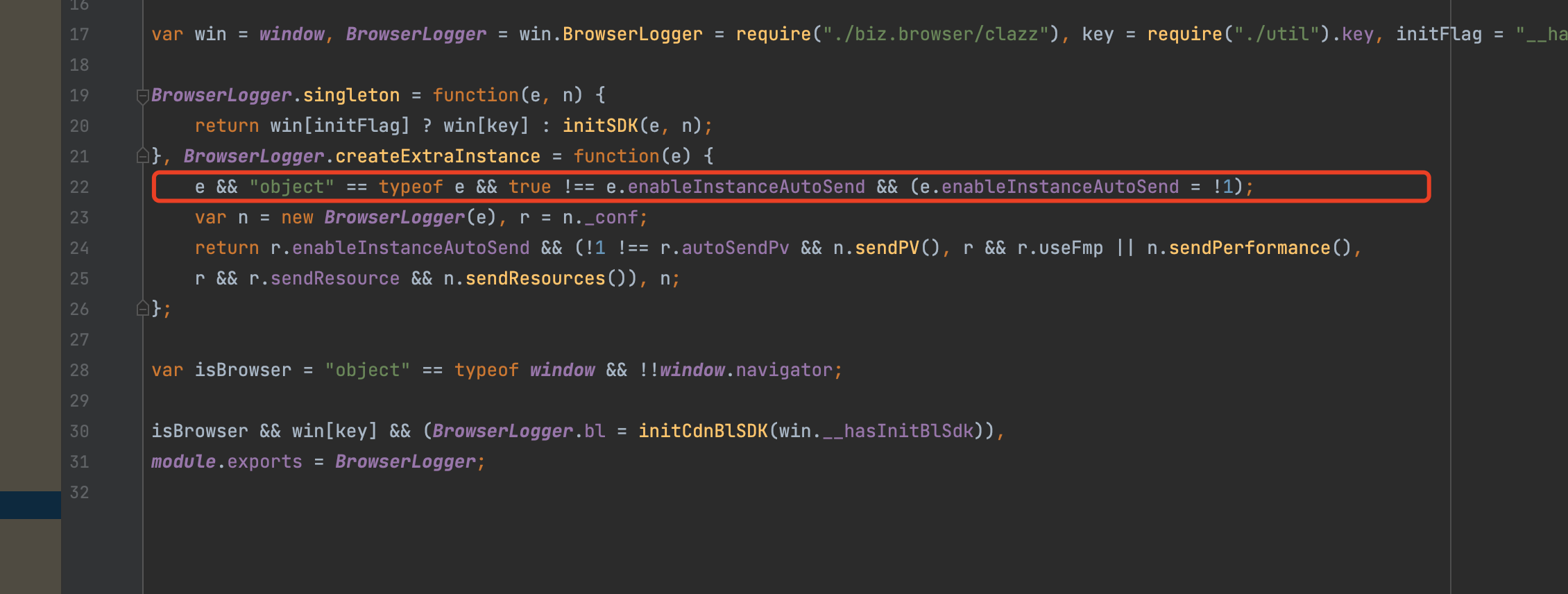
如果不打开,那你创建的这个实例不会自动上报,只能手动调用new出来的对象去做一点微小的工作。
单例和实例,无脑加就可以,如下图: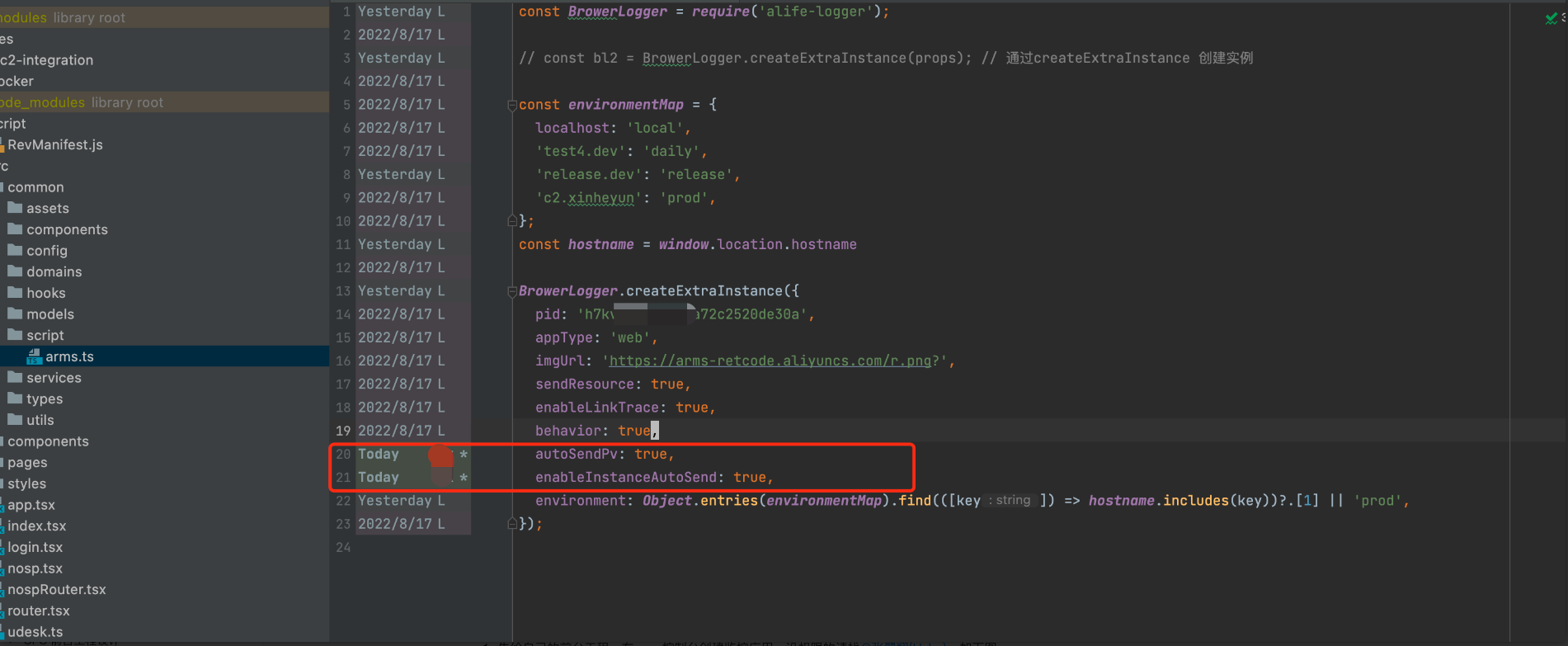
具体操作是:
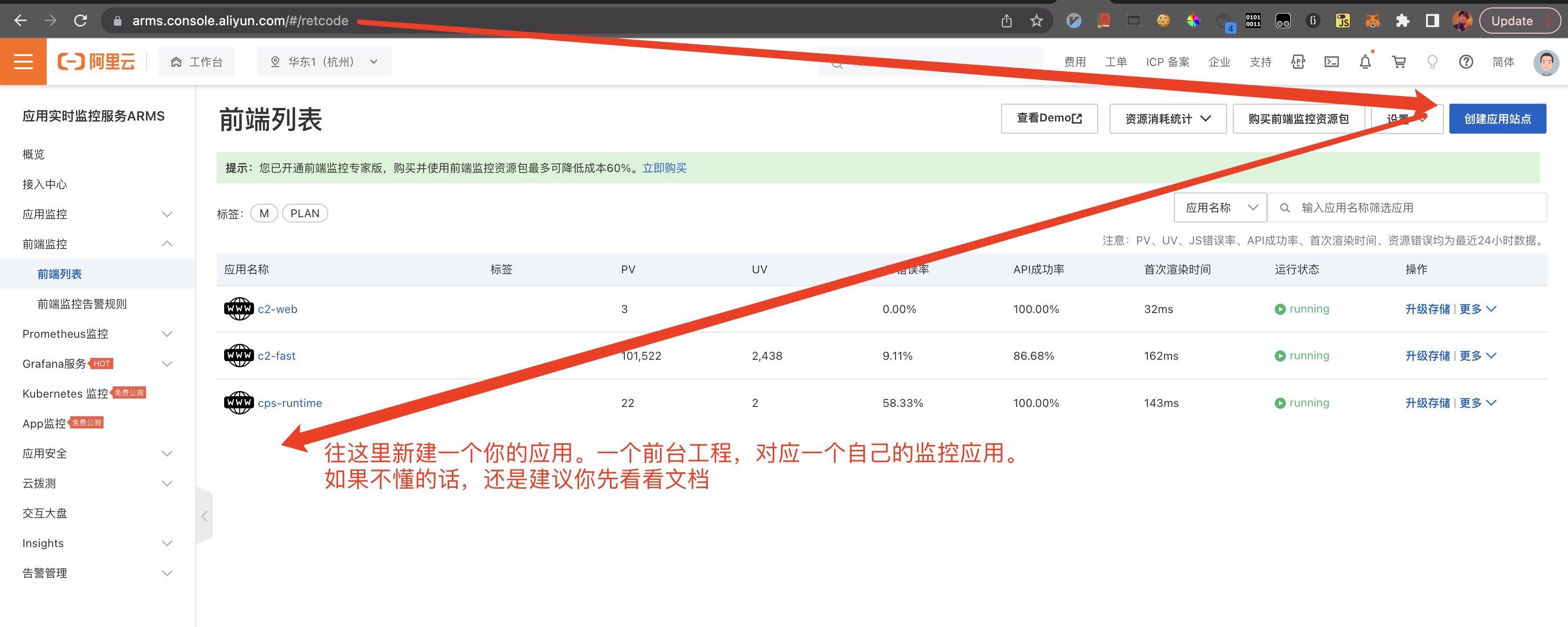
- 先给自己的前台工程,在arms控制台创建监控应用,如下图
- 把探针,加入到你的代码里,官方入口如下图,但我不推荐 你这么做,请直接跳到第3部,这里的图你看看就好,除非你想自己探索一下
- 在工程的入口文件(你webpack打包的entry)加入如下代码,这就是探针了:
const BrowerLogger = require('alife-logger');
const environmentMap = {
localhost: 'local',
'test4.dev': 'daily',
'release.dev': 'release',
'c2.xinheyun': 'prod',
};
const hostname = window.location.hostname
BrowerLogger.createExtraInstance({
pid: '', // 换成你自己arms监控项目的pid,每个业务工程在arms控制台单独创建一个
appType: 'web',
imgUrl: 'https://arms-retcode.aliyuncs.com/r.png?',
sendResource: true,
enableLinkTrace: true,
behavior: true,
autoSendPv: true,
enableInstanceAutoSend: true,
environment: Object.entries(environmentMap).find(([key]) => hostname.includes(key))?.[1] || 'prod',
});
- 自己决定是否设置uid,自己查文档,推荐是uid设置一个staffid,然后通过自定义字段设置租户id,但是
租户+staffID拼接的方法不是很好;不设置也没有任何关系,设置了只是让你知道是哪个用户遭殃了而已,并且后期可以根据这个聚类,做到“让我们来看看富光今天哪个员工被我的代码恶心到了?”- 这里科普两个概念:
事故定级和故障影响面,如字面意思。 - 通过这些东西的聚类可以分析出具体数据。当故障真实发生的时候,我们不会像个瞎子一样,只能等客户投诉,而可以通过数据知道哪些用户遭遇了什么。
- sls监控相对客户端监控来说是滞后的,服务器的access、api的请求,这些数据产生的前置条件是网络是通的,请求是能发起的。这样客户的请求才能打到网关,才能access你的服务,否则连log的机会都没有。
- 前台服务是通过ngx转发到oss来提供静态资源。
- ngx响应后,到真正有请求再次打到后台服务前,中间的过程对sls来说是黑盒子。
- 这里科普两个概念:
- 从内部环境向上发布,直到进入生产环境: eden+test -> release -> 生产;这个过程中,在控制台大盘上,逐步观察是否正确产生数据。
会不会造成额外性能开销?
- 会的,但同时出现的instance最多有2个(就目前c2的应用设计情况来讲)。
- qiankun的js是分段跑的,arms只是在子应用里多加一丢丢代码片段,这与整个架构比根本不是一个量级,可以忽略。
- 在乎这点性能开销,还不如把自己代码优化一下来的实在。
接下来?
数据统计需要更精细,更准确。目前的数据只是能采集到了,但未必精确,甚至一些配置也可能有问题。进一步可能需要再针对采集的过程进行定制化。
比如首屏速度,在爹应用统计数据是150ms,这就很扯淡了,从使用体感上,cps的首屏至少在3000ms以上才是正常范围。那儿子应用统计的就对吗?onload已经发生了,怎么判断这段js的开始渲染和首屏结束?对于业务来说这可能不是很重要,但对于cps来说,这个数据就非常有参考意义了。
再比如,以cps的表单为例,我们的业务是多元化的,但我们的路由是标准的,所有表单都是/metadata/template/xxxx 我们既需要知道哪些表单是比较牛逼的,因为搭建的内容复杂度会一定程度上影响这个页面的性能,同时我们也要知道所有表单的平均表现,只统计到/metadata/template/这一级就好,然后我们还需要知道这两组数据的方差,来判断我们的代码性能,理论上搭建复杂度对性能的影响越小越好。
再再比如,我只需要用户线上使用cps时候的数据,而不需要我们内部nosp的数据,这在目前又是不可能做到的,这个在做起来就会产生额外的arms配置去过滤,但一些基础性能数据可能会被默认统计,是过滤不掉的,因为在代码层面,这些东西是耦合在一起的;这就依赖于在漫长的迭代中逐步进行架构升级,才能实现准确监控。
qiankun这种把业务拆分开的框架,在这种基建能力上的考虑是非常简陋的,你去社区,github issue寻求解决方案,几乎没什么有用信息;像应用监控这种基础诉求,甚至没有一个官方的标准实践,他们只管杀不管埋。所以除了监控,未来一定会发现更多基建诉求在框架层面被套牢,而那时候我们能依赖的,希望不仅仅是自我摸索,毕竟我们是一个以业务主打的非科技公司。
下一步要进一步精确统计项目,需要利用arms的api,去ignore掉其他子应用的业务。
举例来说:
- metadataapp工程
- /metadata/template_manage
- /metadata/template/xxx
- manufacture工程
- /product/xxxx
- /job/xxxx
- erp工程
- /order/xxx
- /warehouse/xxx
假设在爹工程下挂载如上三个工程,每个工程内定义了自己的页面路由
在matadataapp的监控中,我需要过滤掉erp和manufacture的路由。这样在这个探针实例上,我只统计了matadataapp的监控数据。
对应arms的api如下: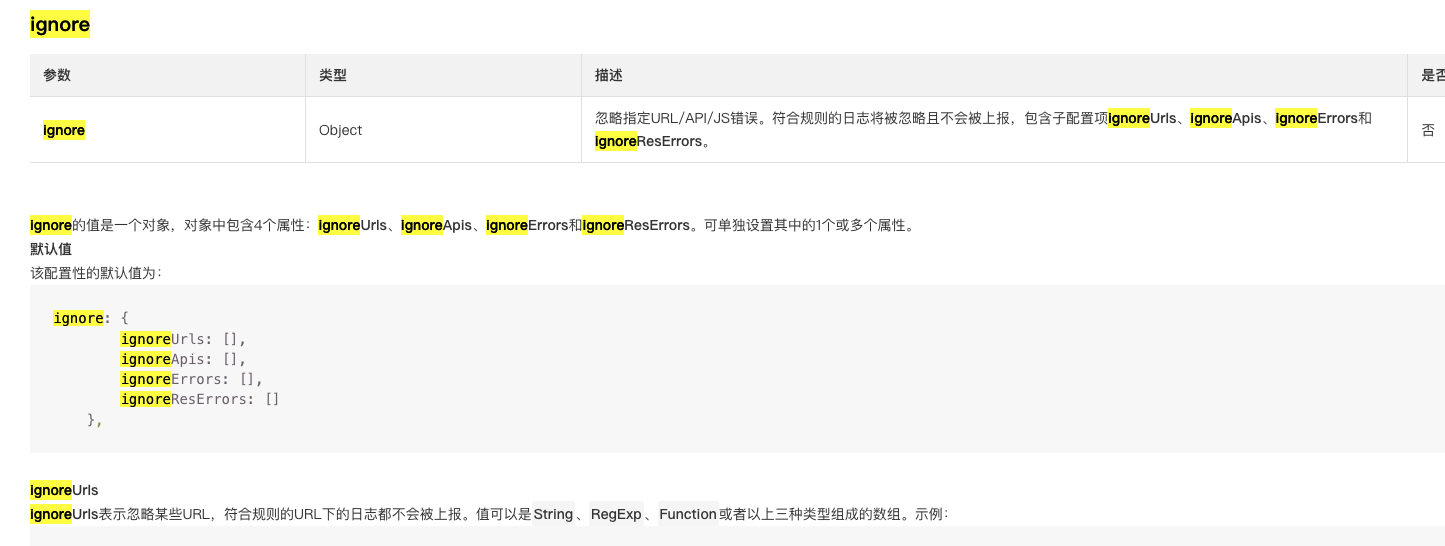
这个api支持正则表达式和方法,因此只需要在工程里,通过该工程的router来过滤,并于本工程保持一致(可以考虑抽象一个路由数组),而无需知道其他业务组的路由规则。
另外,使用单独实例并不是唯一的方案,另一种方案可以是在子应用中动态覆盖爹应用的配置;这种方法我试过后觉得不靠谱,因为乾坤并不是自身js的异步彻底执行完之后再去初始化子应用,这不是严格的串行过程,最终可能导致爹应用又统计不准了。当然这个可能是我没玩明白,或者样本数据太小导致的。所以也等我研究研究再说吧。
